
API Retry Mechanism

APIs are the backbone of the software systems, but they operate in environments where the failure is inevitable. Sometimes, the network is unreliable, server gets overloaded or maybe a deployment has introduced a brief instability. The retry mechanism exists to handle these temporary failures by re-attempting a failed API call, instead of immediately throwing an error.
The retry mechanism is a controlled logic that improves reliability of the systems when implemented correctly. However, if the logic is poorly written, it increases the latency, overload services and makes failure harder to diagnose.
Let us walk through this blog to understand API retires, when they make sense, and where engineers might go wrong.
Why API Calls Fail in First Place?
Before diving into the retries, we need to understand why the API calls fail in the first-place. Most of the failures are not caused by the incorrect logic but due to various other reasons like -
Network Issues: This is a very common reason, why the API call fail. Packet loss, DNS resolution issues, or connection reset can cause the API requests to fail even when the services are healthy and responding. The network failures are often short lived and often succeed on a second attempt.
Timeouts: Another frequent cause is the timeouts. A service may be running fine but may have temporarily slowed down due to some bottleneck, garbage collection pauses or dependency latency. If the client’s timeout expires before a response is returned, the API call fails even though server may eventually complete the request.
5xx Server Errors: Other than above two issues, there are 5xx errors, which indicate that the server has accepted the request but failed to process it. Errors like 503 (Service Unavailable), and 504 (Gateway Timeout) are often signals of overload.
In contrast to 5xx errors, 4xx client errors generally indicate a permanent failure. Retrying a malformed request, an authentication failure, or a missing resource will not fix the problem. These failures should fail fast and be surfaced immediately.
Speaking from personal experience, I’ve made some mistakes in a production system while implementing retry mechanism, which ended up causing duplicates orders, unnecessary errors and wasted resource utilization. But lessons learned the hard way tend to stick, so with that in mind, let’s move on to the next part.
When Retries Make Sense and When They Don’t
Retries are useful only when the failure is likely to be temporary and the request can be safely repeated.
Read operations and idempotent write operations are typically safe to retry. Fecthing user data, querying a catalog, or updating a resource with a known state are examples where repeating the request doesn’t change the outcome.
On the other hand, retries become dangerous when dealing with non-idempotent operations such as creating orders, charging payments, or triggering some side effects in event driven system. Retrying these requests without protection can lead to duplicate actions and inconsistent state.
Retries should also be avoided when the downstream service is already under heavy load. Blindly retrying failing requests can push an already struggling service into complete failure.
How Retry Mechanism Works?
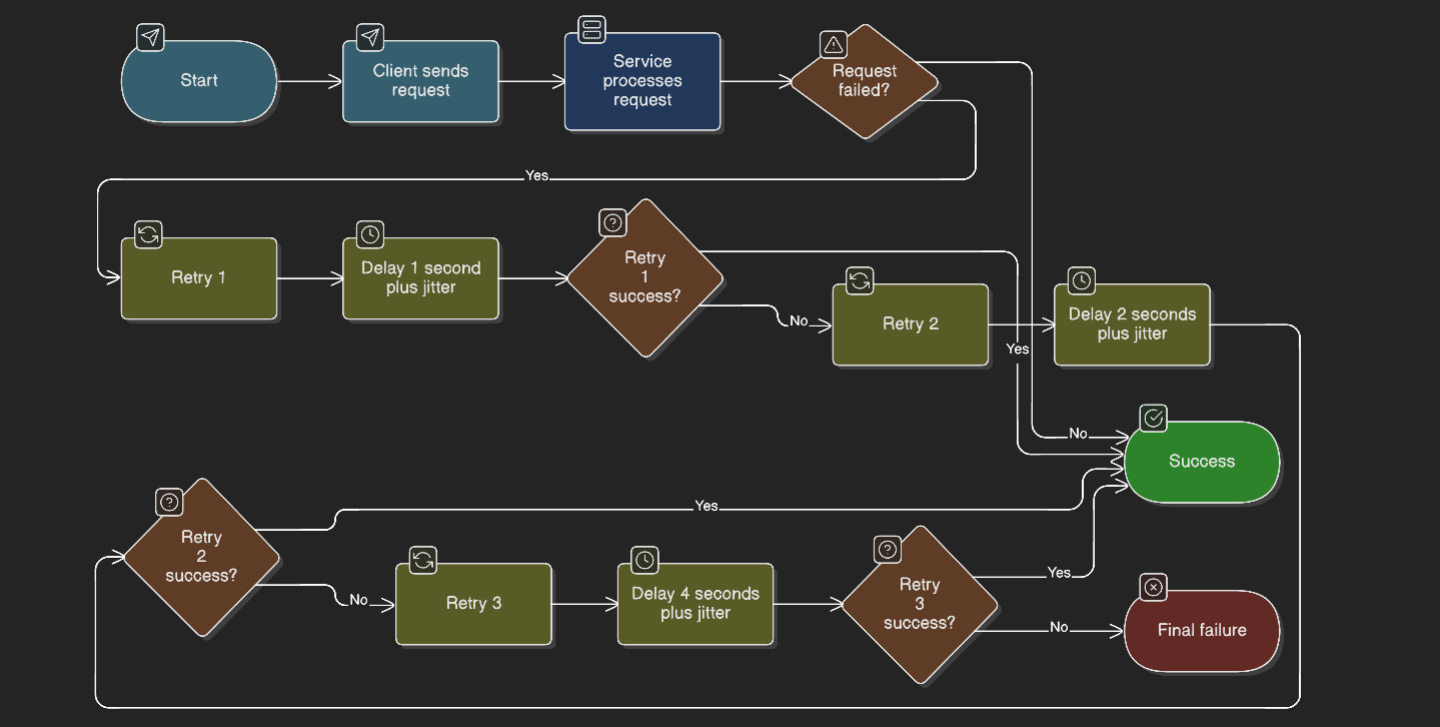
A retry mechanism is more than just “try again.” It is defined by few key parameters that control its behaviour.
The first is the number of retry attempts. Most systems limit retires to a small number, often two or three. Beyond that, the probability of success drops while latency and system load increase.
The second is retry delay, which determines how long a client should wait before retrying. Immediate retries are bad idea and should not implemented in production systems because they tend to hit the downstream service at its weakest point.
To address, this systems use exponential backoff, where the delay increases after each failed attempt. As the name suggests, the first request might wait 100 milliseconds, the second 200 milliseconds, the third 400 milliseconds, and so on. This gives the downstream service time to recover and reduces the traffic spikes.
However, at scale the exponential backoff alone is not enough. If thousands of clients fail at the same time, they will retry at the same intervals, causing synchronized bursts of traffic. To handle this, jitter comes in. Jitter adds a small amount of randomness to the delay so that retries are spread out over time rather than happening simultaneously.
Let us understand with example:
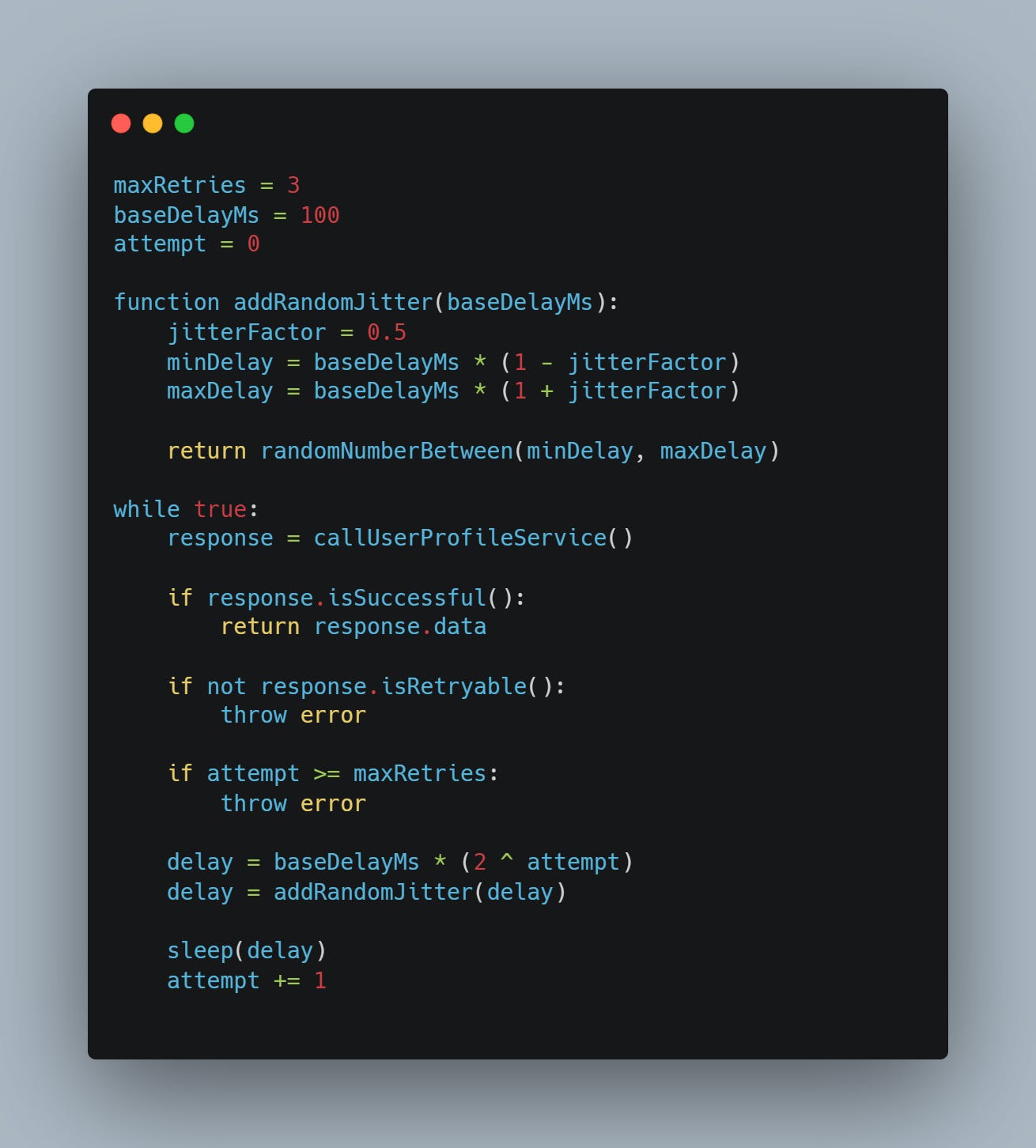
Consider a service that needs to fetch user profile data. Occasionally, the downstream service returns 503 error due to brief overload.
A reasonable retry strategy would attempt the call again a limited number of times, retry only on retry-able errors, and gradually increase the delay between attempts. If all retries fail, the error should be propagated so that higher-level logic can decide how to respond.
Here is a minimal pseudo-code that demonstrated this approach:
Common Pitfalls to Avoid
One of the most common mistakes is retrying non-idempotent requests without safeguards. A timeout doesn’t mean the server has failed to process the request. Retrying might cause the same action to be executed twice.
Another frequent issue is “retry storms”. When a service goes down, all callers start retrying aggressively which in turn increases load on the server and prevents recovery. This usually happens when retry logic is configured without backoff, jitter, or limits.
While implementing the retry mechanism one must keep in mind that retries have direct impact on the latency. Each retry adds waiting time. In user facing systems, excessive retries can lead to long response times and poor user experience.
Best Practices
The retry mechanism must be used intentionally and not as a default setting. Only retry failures that are know to be transient. Always combine retries with timeouts, exponential backoff, and jitter. Keep retry counts low and make retry behavior observable through metrics and logs.
For write operations, design the APIs to be idempotent or provide the idempotency keys.
Above all, the retry mechanism improve the system reliability only when they are designed with clear understanding of the failure modes and system behaviour.
That will be all from my side for this blog.
Happy Learning!!